

Kunstig intelligens
Forklarlig AI: Hvordan vægter AI–modeller data?
Katrine Hommelhoff Jensen, Senior Computer Vision and Graphics Specialist, PhD
Når vi taler om forklarlig kunstig intelligens, så er omdrejningspunktet tit, hvordan vi får forklaret computerens beslutningsproces, så alle kan forstå det. Det er dog ikke kun i teknologiens møde med slutbrugeren, at forklaringer har værdi. Når vi udvikler ny teknologi, kan forklaringer illustrere, hvordan en model vægter data i sin beslutning, og herunder hvad der måske vægtes uhensigtsmæssigt. Den information kan så bruges til at justere sammensætningen af den data, vi træner på og selve træningsprocessen, så vi kan forbedre vores model.
Med et konkret eksempel vil jeg illustrere, hvordan passivt staldinventar, som en jernlåge, kan have en negativ effekt på en models evne til at detektere fødslen af pattegrise, og dermed sikkerheden af det system, som skulle hjælpe landmanden med at overvåge fødslerne.
Men først lidt baggrundsinformation…
Når en so går i fødsel, så har den i gennemsnit knap 18 pattegrise indeni sig, der venter på at komme ud. De mange små grise har en lang vej og risikerer at dø af iltmangel på vejen i livmodersækken. I den ideelle verden ville landmanden have al tid i verden til at stå klar og vente på, at soen gik i fødsel, så han kunne hjælpe pattegrisene på vej, hvis der gik for lang tid mellem fødslerne. Men i det moderne landbrug skal landmanden overvåge mange farende søer og risikerer at overse, hvis en so har problemer under en fødsel, og det kan betyde døden for op til en fjerdedel af pattegrisene, viser studier.
Vi har hjulpet firmaet FarrowTech med at udvikle software til et system, der kan overvåge fødslerne. Løsningen består af et infrarødt kamera, der i reel-tid detekterer fødslerne og transmitterer hvert fødselstidspunkt til en server, som kommunikerer med en app på landmandens smartphone. Appen giver landmanden besked, hvis der går for lang tid mellem to fødsler. På den måde kan landmanden målrettet tilse de søer, som har akut behov for hjælp, og derved redde flere pattegrise uden at investere i ekstra arbejdskraft. Vi har udviklet billedbehandlingen til løsningen, det vil sige den algoritme, der som input tager en sekvens af billeder fra det infrarøde kamera og detekterer, om der er en fødsel i gang eller ej. Algoritmen er en kombination af klassisk statistisk analyse og billedbehandling med et dybt neuralt netværk til klassifikation af fødselsrelaterede events. Anvendelsen af en forholdsvis tung model til reel-tids-detektion på et kamera med begrænset beregningskapacitet er realiseret med en forudgående statistisk analyse af varmeintensitetsværdierne, som lærer om normaltilstande undervejs, og kun kalder netværket, hvis der opstår en usædvanlig varme — hvis der, med andre ord, er sandsynlighed for en fødsel.
Og så nærmer vi os pointen!
For det dybe neurale netværk bag modellen er blandt andet trænet ved hjælp af forklaringer.
Konturerne i de billeder, vi arbejder med, er beskrevet via deres varmeinformation, og derfor kan det være svært at adskille en nyfødt pattegris fra for eksempel soens inderlår, som kan være lige så varmt som en nyfødt pattegris, hvis den har ligget på det, og så lægger sig om på siden. Idet varmeinformationen i billedet er en grov tilnærmelse til virkeligheden, kan det desuden være svært at kende forskel på en helt nyfødt pattegris, og en som blev født 5 minutter før. Dette er delvist håndteret med en implementering af tracking af pattegrisene, så de kan udelukkes fra analysen efter fødslen, men i visse tilfælde kan en næsten-nyfødt pattegris ’opstå’ i billedet efter at være blevet skjult bag ved soens ben eller andre pattegrise. Et par eksempler på fødsler og ikke-fødsler, som ligner hinanden, er illustreret på Figur 1. Alt i alt stilles der store krav til en fødselsklassifikationsmodel, der skal klassificere situationer korrekt, som kan være svære for det menneskelige øje at skelne fra hinanden.
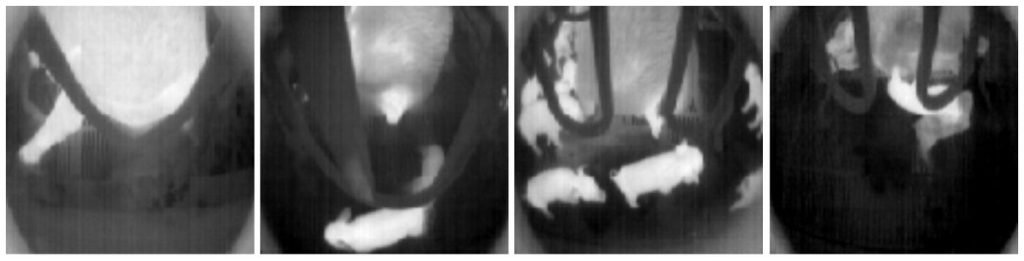
Figur 1
Figur 1: Eksempler på forskellige situationer i frames fra det infrarøde kamera. Billede 1–3 er almindelige situationer, og billede 4 er fra en fødsel. Kameraet er monteret på lågen til faringsstalden og peger på soens bag.
Træning af neuralt netværk
Når man træner et neuralt netværk, kan en fristende fremgang være at fodre det med mest mulig data og simpelthen udvide træningssættet med nye eksempler, som det tog fejl af. Men hvad hvis netværket så stadig ofte fejlfortolker ny data? Hvad skal der til? Målet med at træne et neuralt netværk er ikke kun at træne det til at virke godt på træningseksemplerne, men at træne det sådan, at det virker bedst muligt på ny data. Med den rette viden inden for computer vision og klassisk billedbehandling kan man måske have opbygget en intuition og stille hypoteser op for, hvordan træningssættet eller netværkets arkitektur, parametre osv. kan ændres for at opnå en bedre evne til at generalisere på ny data. Dette løser dog ikke direkte de udfordringer, der er ved at fortolke på opførslen af den ’sorte boks’, som et neuralt netværk er.
Heldigvis er der kommet en ny type analyseværktøj til, som kan hjælpe både specialisten og novicen til at komme hurtigere i mål. Det er anvendelsen af sådan et værktøj, vi vil illustrere med FarrowTech-dataen og staldinventaret som eksempel.
I den seneste tid er der kommet en række forskellige værktøjer til, som trækker informationer ud af et neuralt netværk, der kan hjælpe til at forklare, hvorfor modellen har taget et bestemt valg på noget data. Disse værktøjer kan være meget specifikke for en særlig type af neurale netværk, og der er da også en hel kategori, som fokuserer på Convolutional Neural Networks (CNNs), som er anvendt i FarrowTech-casen til klassifikation af billeder.
Disse individuelle forklaringer af valg kan fokusere på flere forskellige dele af netværket; den ideelle, omfattende forklaring fra input til output findes (endnu) ikke. Typisk tager man udgangspunkt i den score (point for hvor sikker modellen er), som netværket har associeret med klassifikationen, og ’går baglæns’ gennem netværket for at se, hvilke elementer i de forskellige lag der har bidraget mest til den score, og hvilke pixels i det originale billede disse elementer er forbundet med. Summen af bidrag forbundet med hver enkel pixel kan så visualiseres som et ’heatmap’, der tydeliggør de relevante områder af billedet. Det vil sige, jo mere en pixel har bidraget til en beslutning, des lysere en farve får den i heatmap’et. En af disse forklaringsmetoder, og dens evne til at tydeliggøre et problem med en dårlig model, er illustreret på Figur 2.

Figur 2
Figur 2: Første række viser fire originale frames fra det infrarøde kamera, alle fra fødsler. De to andre rækker viser de korresponderende heatmaps, produceret med forklaringsværktøjet tfexplain og metoden GradCAM (https://github.com/sicara/tf-explain): Jo lysere pixels, des vigtigere var de for fødselsklassifikationen. Række 2 er heatmaps produceret med en model A, som er trænet på data fra én stald. Række 3 er heatmaps produceret med en model B, som er trænet på data fra flere forskellige typer af stalde og staldinventar. Der ses en tydelig forskel i fokus — model B fokuserer hovedsageligt på den nyfødte pattegris, og model A har associeret en fødsel med jernlågen foran soen.
Og så er vi kommet til jernlågen, hvis rolle i modellen og effekt på modellens evne til at klassificere ny data korrekt, ikke havde været tydelig uden brugen af et forklaringsværktøj.
Forklaringsværktøjet har samtidig skabt evidens for, hvad der skal til for at opnå en bedre model. For mens vores første model virkede godt i den stald, den var trænet på, så registrerede den ikke fødsler lige så effektivt i en ny stald. Men hvorfor? Opstillingen med kameraet bag den farende so er den samme, og der sker de samme ting i de to stalde.
Som forklaringsværktøjet tydeligt kaster lys på i Figur 2, så viser det sig, at modellen har lært at koble en fødsel sammen med jernlågen foran soen, også selvom jernlågen er til stede i alle frames, og selvom zoom, vinkel samt soens afstand fra lågen varierer i træningssættet. Da en faresti er lille, ligger soen ofte helt tæt på jernlågen, som ofte helt eller delvist overlapper med den pattegris, som bliver født. Og hvad kan vi så gøre med den information? Vi ved nu, at modellen ser på andre ting end pattegrisen, når den klassificerer en frame som en fødsel, og dette ofte i overvejende grad. Vi ser også, at modellen kobler elementer i billedet, vi ved fra vores menneskelige syn, ikke har nogen relevans for forståelsen af en fødselssituation. Dette er en god indikation for, at vi skal have løsrevet modellen fra denne ’misforståelse’, og at vi ved at gøre det får en god chance for at opnå en bedre model. Løsningen er at udvide træningssættet med optagelser fra andre stalde med en anden type staldinventar. Dette er bekræftet af illustrationerne fra forklaringsværktøjet for klassifikationen af de samme billeder med en ny model, som er trænet på data fra flere forskellige stalde med forskelligt staldinventar. Her ses det, at modellen hovedsageligt fokuserer på pattegrisen, som bliver født, samt området omkring — og ikke på jernlågen.
Et neuralt netværk skal altid evalueres på, hvor godt det klarer sig på ny data. Men forklaringsværktøjer og evidens for modellens opførsel skaber nogle muligheder for at analysere dens egenskaber, som kan effektivisere udviklingen. Desuden åbner det op for en formidling, der rækker langt udover specialisten, der typisk sidder bag de teoretisk tunge modeller. Som i mange tilfælde i dag er kunden, som FarrowTech, herre over sin egen data og den drivende kraft bag udvindelsen af data og konstruktionen af datasæt. Dette koster tid og penge for kunden. Med forklaringer som evidens kan specialisten stille mere præcise krav til, hvor meget data det er nødvendigt for kunden at fremstille for at komme i mål med en god model.
I tilfældet med FarrowTech har forklaringer vist, at det var nødvendigt for dem at investere tiden til at indsamle data fra flere forskellige stalde, før modellen kan sættes i produktion. Forklaringer kan hjælpe alle i den stadigt voksende gruppe brugere af neurale netværk til at spare tid og implementering — og ikke mindst undren over, hvor skoen trykker.
Er artiklen ikke forklarende nok, er du velkommen til at skrive til katrine.hommelhoff@alexandra.dk.